Why Some Verticals Have Stronger Multi-Contact Data
Some industries naturally produce deeper contact coverage than others. Learn why certain verticals generate stronger multi-contact data and how it improves outbound targeting and campaign resilience.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
3/7/20264 min read
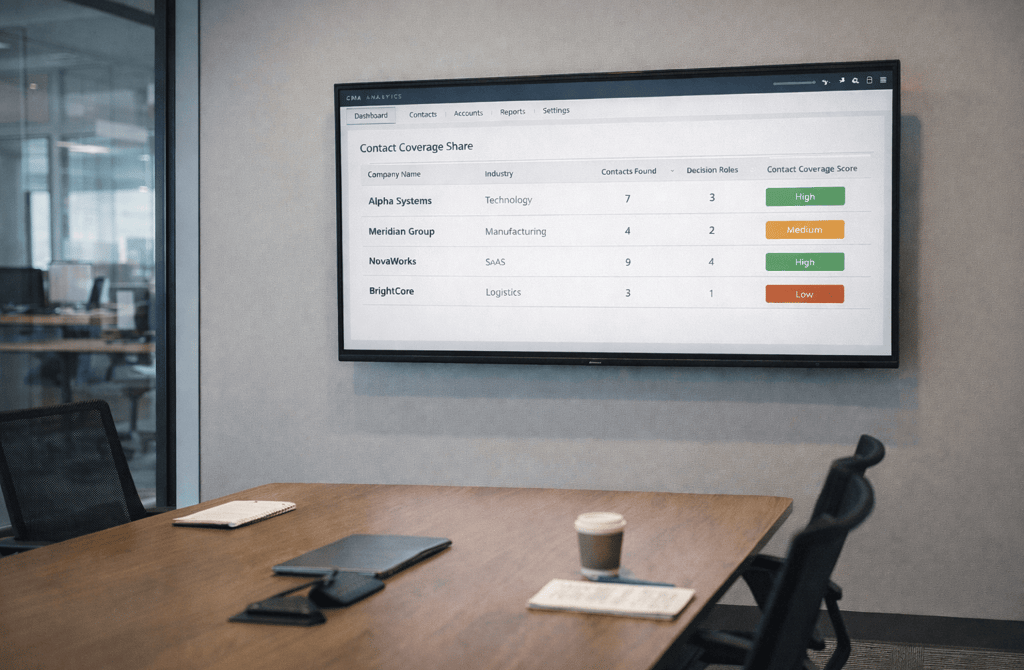
Outbound teams often assume that every company in a dataset should contain a similar number of usable contacts. If one account has eight reachable decision-makers while another has only one or two, the instinct is to blame the data source or validation process.
In reality, those differences often reflect the structure of the industry itself.
Some sectors naturally generate deeper, more complete contact coverage because their internal organizational models require multiple specialized roles. Other industries operate with leaner teams where responsibilities are concentrated among a smaller number of executives. These structural differences quietly shape how strong multi-contact datasets become across different verticals.
Organizational Breadth Drives Contact Density
Industries that depend on layered operational structures typically produce richer contact coverage within each company. These organizations maintain specialized departments responsible for areas such as procurement, technical evaluation, compliance, and operational implementation.
Because responsibilities are distributed across multiple teams, more individuals become relevant to purchasing decisions. Outreach databases can capture contacts from several departments, creating stronger account coverage across the organization.
In these environments, a single company may produce a network of decision-makers and influencers rather than a single point of contact. This naturally strengthens multi-contact data depth.
By contrast, industries with simpler operational models often concentrate decision authority among a small leadership group. The same executive may oversee procurement, technology adoption, and vendor selection simultaneously. Even well-maintained datasets may only surface a handful of viable contacts within each account because the organizational structure simply does not contain many more.
Decision Networks Vary by Sector
Multi-contact data also reflects how influence flows through the buying process.
In industries where decisions require cross-functional input, multiple stakeholders become part of the evaluation cycle. Technical teams assess implementation risks, procurement teams evaluate pricing and contracts, and leadership teams review long-term strategic alignment.
Because these decision networks span multiple departments, databases often capture contacts across the entire buying group. Outreach teams gain the ability to engage several roles simultaneously, improving the resilience of outbound campaigns.
In other industries, purchasing decisions may follow a more centralized path. A single executive or department holds the authority to evaluate and approve new tools or services. When that happens, fewer contacts are recorded within each company profile because the decision process itself involves fewer participants.
Operational Transparency Influences Data Coverage
Another factor affecting multi-contact data strength is how transparent companies are about their internal structures.
Some industries maintain highly visible leadership and departmental information. Employees frequently publish detailed profiles, role descriptions, and organizational affiliations through professional networks and corporate websites. These signals allow data collection processes to identify multiple contacts within the same company more easily.
Other sectors operate with far less public visibility. Smaller executive teams may maintain minimal public presence, and internal department structures are often less clearly documented. Even when companies employ large teams internally, fewer signals exist for identifying individual roles externally.
As a result, multi-contact datasets appear thinner in these verticals, not because the companies are smaller, but because fewer signals exist to map their internal structure.
Why Multi-Contact Coverage Matters for Outbound
Strong multi-contact coverage significantly improves outbound reliability. When outreach depends on a single contact within an account, campaign performance becomes vulnerable to role changes, inbox filtering, or simple lack of interest.
When several relevant contacts exist within the same company, outreach becomes far more resilient. Different roles may respond to different value propositions, and communication can adapt to the perspectives of multiple stakeholders within the organization.
Understanding which industries naturally support deeper contact networks allows teams to plan their outreach strategies more effectively. In sectors where decision-making involves many participants, targeting multiple stakeholders becomes essential for reaching the full buying group.
This is where structured industry segmentation becomes valuable. When working with organized datasets such as a Tech Media and Telecom companies database, teams can observe how contact density varies between sectors and design account strategies that reflect those structural realities.
What This Means
Multi-contact data strength is rarely accidental. It emerges from the internal structure of the industries being analyzed.
Markets with distributed responsibilities and cross-functional decision processes naturally produce richer contact networks within each company. Markets with centralized authority structures tend to produce fewer visible contacts even when companies are well documented.
Outbound teams that recognize these structural patterns gain a clearer understanding of what strong account coverage actually looks like within each vertical.
When contact density aligns with how industries organize their decision processes, outreach becomes more stable and easier to scale. When those structural differences are ignored, teams may misinterpret perfectly normal industry behavior as a problem with the data itself.
Related Post:
Why CRM Metadata Conflicts Corrupt Segmentation
The Lifecycle Management Mistakes That Block Deals
How Scoring Drift Creates False High-Priority Leads
Why Strong Scoring Depends on Field Completeness
The Multi-Signal Scoring Framework That Actually Works
How Inconsistent Metadata Breaks Your Segmentation Logic
Why Metadata Drift Happens Inside Large Lead Lists
The Contact-Level Clues Buried Inside Metadata Fields
How Company Expansion Alters Contact Accuracy
Why Lifecycle Drift Skews Segmentation Over Time
The Stage-Based Patterns That Predict Reply Probability
How Source Diversity Boosts Lead Accuracy at Scale
Why Multi-Source Data Requires Stricter Deduplication
The Blending Rules That Prevent Data Integrity Loss
How Bad Data Bloats Sending Volume With No Returns
Why SDR Teams Burn Out When Lead Data Is Faulty
The Compounding Waste Caused by Outdated Lead Lists
How Data Drift Disrupts Revenue Decision-Making
Why Revenue Systems Require Continuous Data Validation
The Data Signals That Reveal Structural Revenue Weakness
How Over-Automation Creates Pipeline Noise
Why SDR Judgment Beats Automation in High-Stakes Accounts
The Blind Spots Inside Automation-First Outbound Systems
How System-Level Data Drift Derails Reliable Email Sending
Why Modern Outbound Systems Rely on Data Interconnectivity
The Data Dependencies Most Founders Never See
How Industry Turnover Drives Bounce Rate Differences
Why High-Churn Markets Produce Unstable Email Data
The Bounce Risk Patterns Hidden Inside Each Industry
How Industry-Specific Roles Influence Email Behavior
Why Certain Verticals Prefer Multi-Step Messaging
The Outbound Timing Patterns Hidden Inside Each Industry
How Sector Stability Predicts Long-Term Data Freshness
Why Fast-Decay Verticals Require More Frequent Validation
The Industry-Level Signals That Reveal Accelerated Data Aging
Why AI Becomes Unreliable With Aged Lead Lists
The AI Pipeline Behind Modern B2B Data Processing
Why LLM-Assisted Validation Requires Clean Metadata
The Vertical Variances That Predict ICP Fit Accuracy
How Industry Complexity Impacts Lead Quality Signals
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.