Why Revenue Systems Require Continuous Data Validation
Revenue systems depend on accurate inputs. Discover why continuous data validation protects pipeline integrity, forecast accuracy, and outbound performance before small errors compound.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
2/28/20263 min read
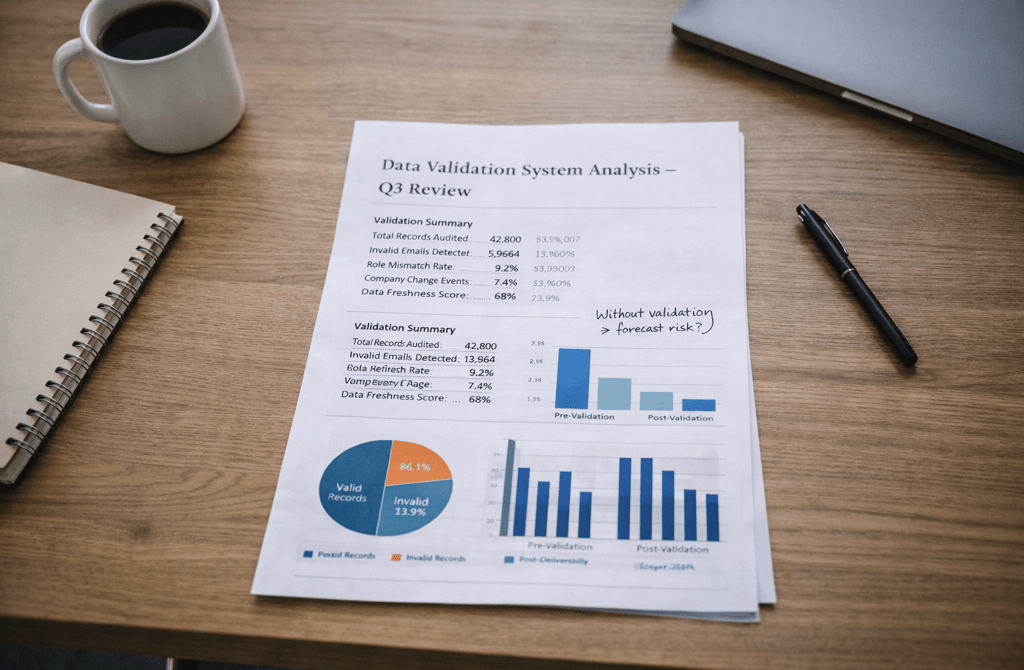
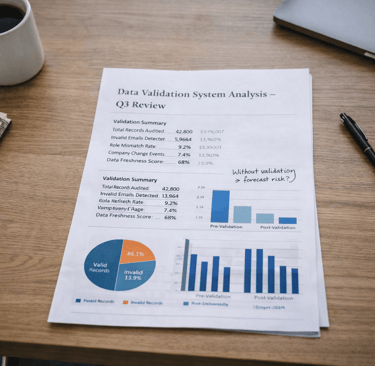
Revenue systems don’t collapse because of one bad campaign.
They drift because their inputs quietly lose integrity.
Every CRM, every forecast model, every pipeline dashboard depends on one assumption: the data feeding it reflects current market reality.
When that assumption weakens, the entire revenue system becomes unstable — even if activity metrics look healthy.
Continuous validation isn’t a hygiene task.
It’s structural protection.
Revenue Systems Are Input-Driven Machines
Modern revenue engines are layered:
Segmentation
Outreach
Qualification
Opportunity creation
Forecast modeling
Each layer inherits the accuracy of the one before it.
If contact data is outdated, role ownership is misclassified, or company attributes have shifted, every downstream metric becomes distorted.
Conversion rates appear weaker.
Forecast confidence declines.
Pipeline velocity becomes unpredictable.
The issue isn’t effort. It’s input quality.
Static Data Breaks Dynamic Systems
Markets move quickly.
Titles change.
Budgets shift.
Departments merge.
Companies restructure.
But many revenue systems operate on quarterly or semi-annual refresh cycles.
That mismatch creates structural lag.
In FinTech B2B lead data, for example, regulatory shifts, funding rounds, and product pivots frequently alter who controls compliance budgets or payment infrastructure decisions. A contact who owned integration last quarter may now sit under risk management, or report into a new function entirely.
If validation cycles don’t capture that shift, targeting logic becomes outdated while the CRM still shows “active opportunity.”
Revenue systems assume continuity.
Markets rarely provide it.
Validation Protects Forecast Integrity
Forecasting relies on stable probabilities.
When you assign a 20% close rate to early-stage pipeline, you’re assuming:
The contact is still in role
The department still owns the problem
The company’s priorities haven’t shifted
Without continuous validation, those assumptions age.
And aging assumptions inflate forecast confidence.
You may still see:
Strong top-of-funnel volume
Healthy meeting rates
Consistent opportunity creation
But if contact authority erodes underneath, late-stage conversion drops unexpectedly.
That’s not a sales problem.
It’s a validation gap.
The Compounding Effect of Unchecked Errors
Revenue systems don’t fail because 5% of records are wrong.
They fail because small inaccuracies stack:
A bounced domain here
A misaligned title there
A department shift unnoticed
A company growth stage change untracked
Each one slightly reduces precision.
Over time, precision loss forces higher volume to compensate.
Higher volume increases operational load.
Operational load masks the underlying cause.
Continuous validation interrupts that cycle before it compounds.
Governance vs Reaction
Many teams validate only after something breaks:
Bounce rate spikes
Reply rates collapse
Forecast misses occur
That’s reactive validation.
Continuous validation is proactive governance.
It means:
Defined refresh intervals
Role ownership re-checks
Company attribute updates
Suppression of invalid contacts before campaigns launch
It treats data accuracy as infrastructure, not cleanup.
Revenue Stability Requires Recency Discipline
Revenue systems are forward-looking by design.
They project.
They allocate.
They invest.
But projections are only stable when recency is controlled.
Without validation discipline, revenue dashboards become historical artifacts — showing activity based on yesterday’s org charts.
When validation is embedded into the system, forecasts reflect current buying authority.
When validation is sporadic, pipeline health becomes an estimate built on aging records — and strategic decisions drift with it.
Related Post:
Why Buyer Fit Accuracy Matters More Than Industry Fit
The Hidden ICP Mistakes That Make Outreach Unpredictable
How Poor Data Creates Blind Spots in Committee Mapping
Why Buying Committees Prefer Consistent Messaging Across Roles
The Contact Layering Strategy Behind Multi-Threaded Sequences
How Engagement Timing Predicts Buying Motivation
Why Intent Data Works Only When the Inputs Are Clean
The Multi-Signal Indicators Behind Strong Reply Rates
How ICP Precision Improves Reply Rate Fast
Why Bad Data Creates False Low-Reply Signals
The Underestimated Variables Behind Reply Probability
How Data Drift Creates False Confidence in Pipeline Health
Why Incorrect ICP Fit Leads to Dead Pipeline Stages
The Drop-Off Patterns That Reveal Data Quality Problems
How Duplicate CRM Entries Kill Data Reliability
Why CRM Metadata Conflicts Corrupt Segmentation
The Lifecycle Management Mistakes That Block Deals
How Scoring Drift Creates False High-Priority Leads
Why Strong Scoring Depends on Field Completeness
The Multi-Signal Scoring Framework That Actually Works
How Inconsistent Metadata Breaks Your Segmentation Logic
Why Metadata Drift Happens Inside Large Lead Lists
The Contact-Level Clues Buried Inside Metadata Fields
How Company Expansion Alters Contact Accuracy
Why Lifecycle Drift Skews Segmentation Over Time
The Stage-Based Patterns That Predict Reply Probability
How Source Diversity Boosts Lead Accuracy at Scale
Why Multi-Source Data Requires Stricter Deduplication
The Blending Rules That Prevent Data Integrity Loss
How Bad Data Bloats Sending Volume With No Returns
Why SDR Teams Burn Out When Lead Data Is Faulty
The Compounding Waste Caused by Outdated Lead Lists
How Data Drift Disrupts Revenue Decision-Making
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.