The AI Pipeline Behind Modern B2B Data Processing
Discover how AI pipelines process, enrich, and validate modern B2B lead data. Learn the stages behind scalable data processing systems used in outbound and RevOps workflows.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
3/6/20264 min read
Most people talk about AI in outbound as if it’s a single tool. A model scores leads, predicts intent, or recommends prospects. But in reality, AI only becomes useful when it sits inside a much larger system.
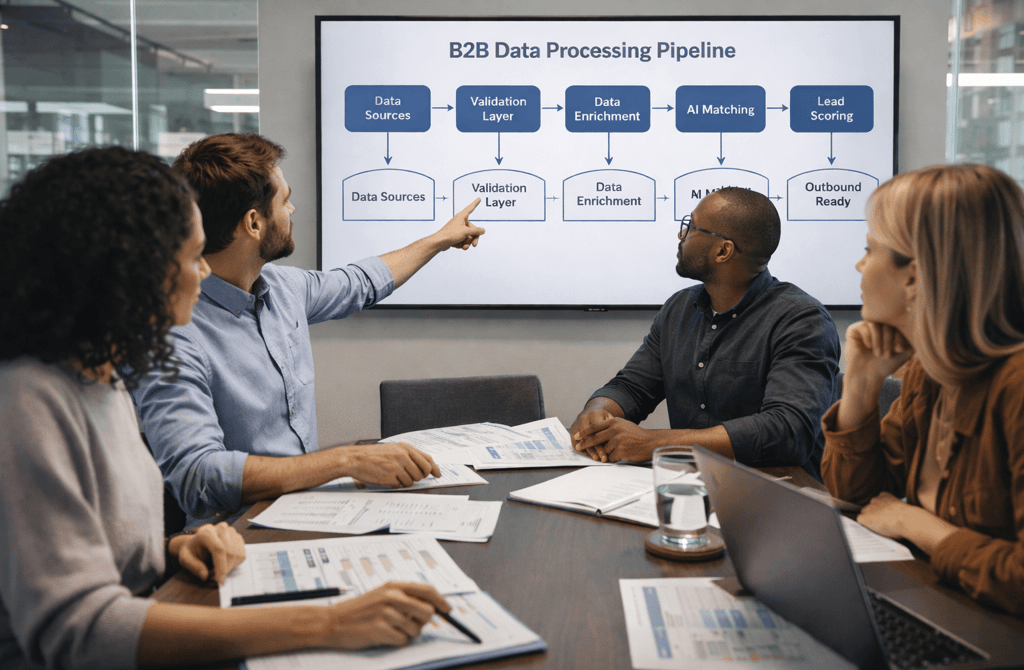
Before any prediction happens, data must move through a structured pipeline—one that cleans, enriches, verifies, and organizes raw records into something AI models can actually understand.
Without that pipeline, AI isn’t analyzing meaningful signals. It’s simply processing noise.
Modern B2B data operations rely on layered pipelines because the raw information entering these systems is messy, incomplete, and constantly changing.
Raw Data Is Only the Starting Point
The first stage of any B2B data pipeline begins with raw inputs. These can come from a variety of sources: scraped company profiles, CRM exports, partner datasets, or third-party data providers.
At this stage, records often contain inconsistencies.
Job titles vary in format. Company names appear in different spellings. Some contact records include missing fields, while others contain outdated information.
If AI models were fed directly with this type of data, their predictions would be unreliable from the start. The pipeline exists to stabilize these inputs before any analysis begins.
Cleaning and Standardization
Once raw records enter the system, the first major step is normalization.
This stage focuses on aligning the structure of the data so that every field follows a predictable format. Titles become standardized. Company names are normalized. Country and region fields are aligned with consistent naming conventions.
This may sound administrative, but it’s one of the most important parts of the entire pipeline.
AI models rely heavily on structured patterns. If two identical roles appear under different titles—like “Head of Growth” and “Growth Lead”—the system may treat them as unrelated signals unless the data is normalized.
Cleaning transforms fragmented inputs into consistent datasets that algorithms can process accurately.
Data Enrichment Expands Context
After normalization, the pipeline moves into enrichment.
This stage adds context that wasn’t present in the original dataset. Company size, industry classification, technology stack indicators, or hiring signals can all be layered onto the record.
Enrichment matters because AI models perform best when they can analyze relationships between multiple variables. A job title alone tells the model very little. But when paired with company growth signals, industry patterns, and department structures, the same record becomes far more meaningful.
The goal isn’t simply to add more data. It’s to create richer signals that allow the model to detect patterns in how organizations behave.
Validation Protects the Pipeline
One of the most overlooked steps in B2B data processing is validation.
Records must be checked continuously to ensure that contact details still exist, domains are active, and organizations remain operational. Without this step, pipelines accumulate silent errors that gradually weaken the entire system.
Validation layers act as quality filters before the data progresses deeper into the pipeline.
For teams focused on Construction industry B2B lead targeting, validation is particularly important because company structures and contractor networks shift frequently. Without frequent verification, lead records can become outdated far faster than teams expect.
The validation layer ensures that downstream AI models are analyzing records that still reflect real organizations and real people.
AI Models Interpret the Structured Dataset
Only after the dataset passes through cleaning, enrichment, and validation does the AI layer begin its work.
At this stage, the model can evaluate patterns across thousands of structured records. It might analyze which combinations of company characteristics correlate with higher reply rates or identify clusters of roles that typically participate in buying decisions.
Because the upstream pipeline has stabilized the data, the AI model is now able to extract meaningful relationships instead of reacting to inconsistencies.
This is why strong data pipelines matter so much. AI performance is rarely determined by the sophistication of the algorithm alone. It depends on how well the system prepares the information before the model sees it.
The Pipeline Is the Real Infrastructure
When people talk about AI transforming outbound, they often focus on the prediction layer—the scoring model or the automated targeting recommendations.
But the real infrastructure sits underneath.
The cleaning processes, enrichment layers, validation checks, and normalization rules form the foundation that allows AI to operate reliably.
Without these stages, AI becomes unstable because the signals feeding the model constantly shift. With them in place, the system becomes far more predictable.
What This Means for Modern Outbound
The strongest outbound systems treat AI as the final stage of a broader data pipeline rather than the starting point.
When raw information is stabilized, enriched, and verified first, AI models can operate on reliable signals. The predictions become more consistent, and outreach strategies become easier to scale.
But when pipelines skip these foundational steps, even advanced models struggle to produce useful guidance.
Conclusion
AI in B2B outreach isn’t powered by algorithms alone. It’s powered by the systems that prepare data before those algorithms begin working.
The pipeline determines whether AI analyzes meaningful signals or simply amplifies inconsistent records.
When the data pipeline is structured carefully, AI becomes a powerful analytical layer that helps teams identify patterns across complex markets.
When the pipeline is weak, the model ends up predicting outcomes based on fragmented inputs.
Reliable outbound systems are built on stable data foundations.
When B2B data pipelines stay clean and structured, AI decisions become dependable.
Related Post:
Why CRM Metadata Conflicts Corrupt Segmentation
The Lifecycle Management Mistakes That Block Deals
How Scoring Drift Creates False High-Priority Leads
Why Strong Scoring Depends on Field Completeness
The Multi-Signal Scoring Framework That Actually Works
How Inconsistent Metadata Breaks Your Segmentation Logic
Why Metadata Drift Happens Inside Large Lead Lists
The Contact-Level Clues Buried Inside Metadata Fields
How Company Expansion Alters Contact Accuracy
Why Lifecycle Drift Skews Segmentation Over Time
The Stage-Based Patterns That Predict Reply Probability
How Source Diversity Boosts Lead Accuracy at Scale
Why Multi-Source Data Requires Stricter Deduplication
The Blending Rules That Prevent Data Integrity Loss
How Bad Data Bloats Sending Volume With No Returns
Why SDR Teams Burn Out When Lead Data Is Faulty
The Compounding Waste Caused by Outdated Lead Lists
How Data Drift Disrupts Revenue Decision-Making
Why Revenue Systems Require Continuous Data Validation
The Data Signals That Reveal Structural Revenue Weakness
How Over-Automation Creates Pipeline Noise
Why SDR Judgment Beats Automation in High-Stakes Accounts
The Blind Spots Inside Automation-First Outbound Systems
How System-Level Data Drift Derails Reliable Email Sending
Why Modern Outbound Systems Rely on Data Interconnectivity
The Data Dependencies Most Founders Never See
How Industry Turnover Drives Bounce Rate Differences
Why High-Churn Markets Produce Unstable Email Data
The Bounce Risk Patterns Hidden Inside Each Industry
How Industry-Specific Roles Influence Email Behavior
Why Certain Verticals Prefer Multi-Step Messaging
The Outbound Timing Patterns Hidden Inside Each Industry
How Sector Stability Predicts Long-Term Data Freshness
Why Fast-Decay Verticals Require More Frequent Validation
The Industry-Level Signals That Reveal Accelerated Data Aging
Why AI Becomes Unreliable With Aged Lead Lists
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.