How Duplicate CRM Entries Kill Data Reliability
Duplicate CRM entries silently corrupt segmentation, inflate pipeline metrics, and distort lead scoring. Here’s how CRM duplication breaks data reliability—and how to fix it before it damages outbound performance.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
2/22/20263 min read
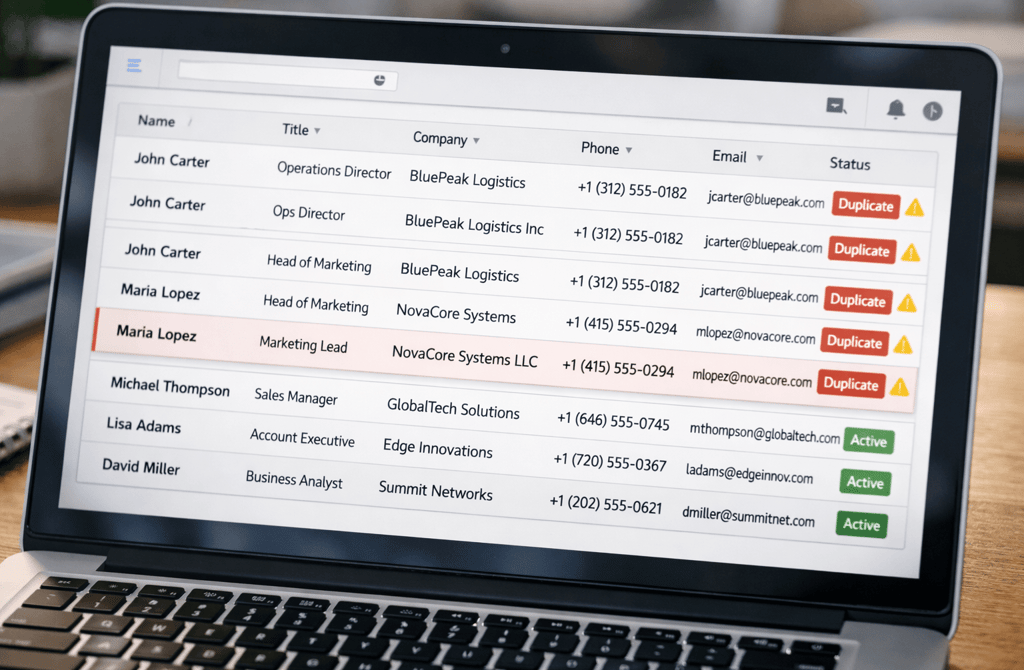
Duplicate records don’t look dangerous at first.
They look harmless. A repeated name. A slightly different job title. A company listed once as “Inc.” and once without it. Most teams assume it’s cosmetic.
It isn’t.
Duplicate CRM entries quietly distort every downstream decision your outbound system makes. They don’t just clutter the database — they corrupt targeting, inflate metrics, confuse automation, and slowly degrade your ability to trust your own data.
And once trust in the CRM drops, everything becomes reactive.
The Illusion of a Bigger Pipeline
Duplicates create a fake sense of volume.
If the same contact exists three times under minor variations, your CRM might show:
Three email sends
Three touches in a sequence
Three entries influencing scoring
But in reality, it’s one person.
This inflates:
Lead counts
Engagement rates
Stage progression numbers
Forecast assumptions
You think targeting is broader than it is. You believe segmentation is working. You assume scoring models are identifying multiple stakeholders. Instead, you’re orbiting the same contact repeatedly.
That’s not scale. That’s distortion.
Segmentation Starts to Break
Segmentation logic depends on clean, unique records.
When duplicates exist, filters start behaving unpredictably:
One version falls into Segment A
Another lands in Segment B
A third remains untagged
Now automation runs conflicting logic across the same account.
This is especially dangerous in complex verticals like cybersecurity decision-maker data, where role precision and department clarity determine whether your message reaches a technical buyer, compliance lead, or executive sponsor.
Duplicates scramble that clarity.
Instead of structured targeting, you get overlap noise.
Lead Scoring Becomes Unreliable
Scoring systems assume each contact represents a single behavioral history.
Duplicates break that assumption.
If one record shows:
Email opened
Link clicked
And another duplicate shows:
No engagement
Marked inactive
Your scoring engine now interprets two conflicting behavioral signals from what is actually one human.
The result?
Artificial score inflation
False “high-priority” flags
Inconsistent prioritization
Your SDR team ends up chasing ghosts while real opportunities get buried.
Multi-Contact Targeting Collapses
Modern outbound increasingly depends on account-level penetration — reaching multiple roles within a buying committee.
But duplicates sabotage that strategy.
Instead of mapping:
CFO
Operations Head
IT Director
You accidentally map:
CFO
CFO (duplicate)
CFO (another variation)
Your CRM shows “three contacts,” but your campaign is single-threaded.
You think you're executing multi-contact outreach. In reality, you're just multiplying noise inside one inbox.
Reporting Starts Lying
Duplicates distort attribution.
They affect:
Conversion rate calculations
Stage-to-stage progression
Reply rate analysis
Bounce reporting
If two duplicate contacts move to different stages, your funnel reports conflicting movement within the same account.
This leads to dangerous misdiagnosis:
“Reply rates are dropping.”
“Our ICP needs revision.”
“Our messaging stopped working.”
When the real issue is structural: your data foundation isn’t stable.
Automation Amplifies the Damage
CRM duplicates don’t stay contained. They ripple outward.
They break:
Email suppression logic
Cadence timing
Workflow triggers
Lead routing rules
Automation assumes structural integrity.
Duplicates violate that assumption.
And the more automated your outbound system becomes, the faster small structural flaws compound into measurable performance decline.
The Psychological Cost: Loss of Data Confidence
There’s an overlooked consequence of CRM duplication: teams stop trusting the system.
When reps suspect:
“This looks like the same person.”
“Why does this account show twice?”
“Didn’t we already email them?”
Confidence erodes.
Instead of relying on data, teams manually double-check, hesitate before sending, and spend time verifying what should already be reliable.
That friction slows everything.
What Actually Fixes It
Deduplication isn’t just about removing identical names.
It requires:
Cross-field matching (email + phone + company + domain)
Title normalization
Company suffix standardization
Continuous cleanup cycles, not one-time audits
Clear suppression rules for merged records
More importantly, deduplication must happen upstream — before segmentation, before scoring, before automation triggers.
Because once duplication spreads across workflows, cleanup becomes exponentially harder.
Conclusion
CRM duplicates don’t just make your database messy. They undermine every performance metric built on top of it.
When records multiply, clarity disappears.
When clarity disappears, targeting weakens.
When targeting weakens, everything downstream suffers.
Reliable outbound isn’t built on volume — it’s built on structural accuracy. And structural accuracy starts with one simple principle: every record must represent exactly one real entity.
When your CRM reflects reality, your campaigns behave predictably.
When it doesn’t, your pipeline becomes noise disguised as progress.
Related Post:
Why Inconsistent Targeting Raises Spam Filter Suspicion
The Inbox Sorting Logic ESPs Never Explain Publicly
How Risky Sending Patterns Trigger Domain-Level Penalties
Why Domain Reputation Is Built on Consistency, Not Volume
The Hidden Domain Factors That Influence Inbox Placement
Why Copy Tweaks Don’t Fix Underlying Data Problems
The Hidden Data Requirements Behind High-Performing Frameworks
Why Framework Experiments Fail When Lists Aren’t Fresh
How Overly Broad Segments Lower Reply Probability
Why Weak Targeting Logic Confuses Inbox Providers
The Real Cost of Using “Catch-All” Segments in Outbound
How Weak ICP Definitions Inflate Your Pipeline With Noise
Why Buyer Fit Accuracy Matters More Than Industry Fit
The Hidden ICP Mistakes That Make Outreach Unpredictable
How Poor Data Creates Blind Spots in Committee Mapping
Why Buying Committees Prefer Consistent Messaging Across Roles
The Contact Layering Strategy Behind Multi-Threaded Sequences
How Engagement Timing Predicts Buying Motivation
Why Intent Data Works Only When the Inputs Are Clean
The Multi-Signal Indicators Behind Strong Reply Rates
How ICP Precision Improves Reply Rate Fast
Why Bad Data Creates False Low-Reply Signals
The Underestimated Variables Behind Reply Probability
How Data Drift Creates False Confidence in Pipeline Health
Why Incorrect ICP Fit Leads to Dead Pipeline Stages
The Drop-Off Patterns That Reveal Data Quality Problems
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.