How Risky Email Patterns Reveal Broken Data Providers
Risky email patterns don’t appear randomly. They’re warning signs of broken data sourcing, weak validation, and unreliable lead providers.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
2/4/20263 min read
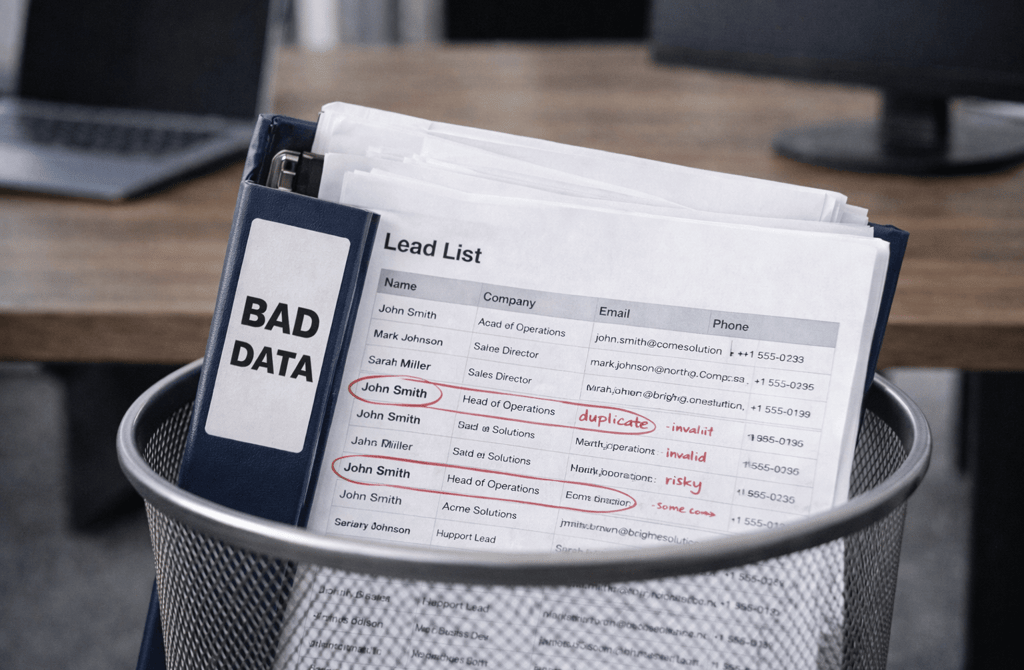
Outbound failures rarely start where teams think they do.
When email performance degrades, the instinct is to inspect subject lines, rewrite copy, slow down sending, or swap tools. Those actions feel productive because they’re visible and controllable. But in many cases, the real problem sits upstream — buried inside the lead data long before outreach begins.
Risky email patterns are not campaign problems. They are sourcing problems.
Patterns emerge at the system level, not the inbox
A single bad email doesn’t mean anything. Neither does one bounce or one spam complaint. What matters is pattern density.
Broken data providers produce lists where:
the same domains appear across unrelated industries
contacts reappear with slightly altered titles or companies
validation results look acceptable, but engagement collapses quickly
inbox placement degrades unevenly across identical campaigns
These are not coincidences. They are structural artifacts of how the data was assembled, cleaned, and resold.
Healthy data behaves consistently under pressure. Broken data fractures.
Why “technically valid” doesn’t mean operationally safe
Most validation processes answer one question:
Does this mailbox exist right now?
That’s a narrow test.
It doesn’t account for whether the address:
has been contacted repeatedly by other senders
exists solely to collect unsolicited mail
is part of a recycled dataset sold multiple times
belongs to a role that no longer exists inside the company
As a result, risky emails pass validation but fail in real usage. They don’t bounce immediately. They simply poison engagement metrics over time.
Inbox providers detect this mismatch long before senders do.
The quiet signals teams overlook
Broken data announces itself through subtle contradictions.
For example:
strong open rates paired with zero replies
domains that never bounce but never engage
sudden spam folder placement after list changes, not volume changes
These signals indicate history — not messaging. Inbox systems remember how recipients behave around similar emails. When that memory conflicts with what your validator reported, the inbox trusts its history.
Why recycled data leaves fingerprints
Data providers under pressure to deliver volume often reuse assets. They don’t fabricate emails; they reshuffle them.
That leads to:
the same contacts appearing across different vertical datasets
slight metadata tweaks masking identical records
inflated “freshness” claims without true resourcing
From the buyer’s perspective, each list looks new. From the inbox provider’s perspective, it’s familiar — and often unwelcome.
This is why risky email behavior clusters around specific providers, not specific campaigns.
When providers optimize for pass rates instead of outcomes
Some providers tune their processes to maximize validation success, not campaign safety.
They focus on:
avoiding hard bounces
passing SMTP checks
producing clean-looking reports
What they ignore:
long-term engagement decay
spam complaints tied to repeated exposure
domain-level trust erosion
That tradeoff isn’t visible on a spreadsheet. It only becomes obvious once the data is put into motion.
Why founders misdiagnose the root cause
Founders often blame themselves first — the copy, the offer, the timing.
That’s reasonable. Messaging is tangible. Data is abstract.
But when multiple campaigns fail in different ways using different frameworks, the common denominator is rarely creativity. It’s input quality.
Bad inputs don’t break loudly. They distort quietly.
How experienced teams interpret risk signals
Mature teams don’t ask whether a list is “good” or “bad.” They ask whether its behavior matches expectations.
They watch for:
consistency across segments
stability across sends
alignment between validation results and inbox behavior
When those elements drift apart, they don’t tweak campaigns. They replace sources.
That discipline prevents small data issues from turning into systemic damage.
Bottom Line
Risky email patterns are not random events and not user error. They are diagnostic evidence.
They reveal how data was sourced, reused, filtered, and packaged. When those patterns appear, the fastest fix is not optimization — it’s isolation and replacement.
Broken data providers don’t fail in obvious ways.
They fail in ways that only become clear once the emails start behaving differently than they should.
Teams that learn to read those signals early avoid spending months fixing problems that never belonged to outreach in the first place.
Related Post:
The Difference Between Syntax Checks and Real Verification
The Bounce Threshold That Signals a System-Level Problem
How Email Infrastructure Breaks When You Use Aged Lists
The Real Reason Bounce Spikes Destroy Send Reputation
Why High-Bounce Industries Need Stricter Data Filters
How Bounce Risk Changes Based on Lead Source Quality
The Drift Timeline That Shows When Lead Lists Lose Accuracy
How Decay Turns High-Quality Leads Into Wasted Volume
Why Job-Role Drift Makes Personalization Completely Wrong
The ICP Errors Caused by Data That Aged in the Background
How Lead Aging Creates False Confidence in Your Pipeline
The Data Gaps That Cause Personalization to Miss the Mark
How Missing Titles and Departments Distort Your ICP Fit
Why Incomplete Firmographic Data Leads to Wrong-Account Targeting
The Enrichment Signals That Predict Stronger Reply Rates
How Better Data Completeness Improves Email Relevance
The Subtle Signals Automation Fails to Interpret
Why Human Oversight Is Essential for Accurate B2B Data
How Automated Tools Miss High-Risk Email Patterns
The Quality Gap Between Algorithmic and Human Validation
Why Human Validators Still Outperform AI for Lead Safety
The Duplicate Detection Rules Every Founder Should Use
How Spam-Trap Hits Destroy Domain Reputation Instantly
Why High-Risk Emails Slip Through Cheap Validation Tools
The Real Reason Duplicate Leads Hurt Personalization Accuracy
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.