The Vertical-Specific Risks Cheap Providers Ignore
Cheap lead providers often overlook industry-specific risks that impact accuracy, deliverability, and targeting. Here’s what breaks across different verticals—and why it matters.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
3/18/20264 min read
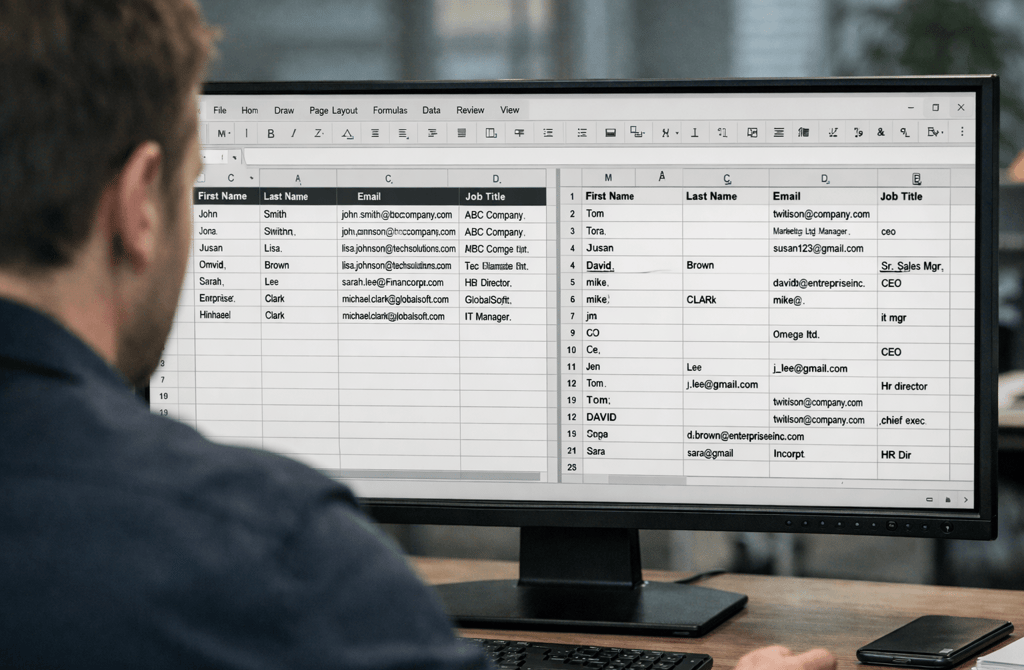

Most lead data looks fine—until you try to use it inside a specific industry.
That’s where things start to break.
Cheap providers usually optimize for volume and speed. They scrape broadly, normalize lightly, and ship datasets that appear structured on the surface. But the moment you push that data into a real outbound system—segmented by industry—the cracks show up fast.
Not because the data is “bad” in general.
But because it’s not built for the vertical you’re targeting.
The Hidden Layer Most Teams Miss
A contact record isn’t just a name, email, and job title.
Inside every industry, those fields behave differently.
Titles don’t follow the same hierarchy
Companies don’t structure teams the same way
Decision-makers don’t sit in the same roles
Even email formats and naming conventions can vary
Cheap providers ignore this layer completely.
They treat all industries as if they follow the same rules.
That assumption is where risk starts.
When Job Titles Stop Meaning What You Think
In one industry, “Head of Operations” might be the decision-maker.
In another, that same title is buried three layers below someone who actually controls budget.
Cheap datasets rarely account for this.
They flatten job titles into generic categories:
CEO
Director
Manager
On paper, it looks clean.
In practice, it creates false targeting confidence.
You think you’re reaching decision-makers.
But you’re actually landing in roles that have zero buying authority in that vertical.
Structural Differences That Break Targeting
Different industries organize differently.
Some are centralized. Others are fragmented. Some rely heavily on contractors. Others operate through layered departments.
Cheap data doesn’t adapt to this.
So what happens?
Contacts get mapped to the wrong function
Departments are mislabeled
Company structures are oversimplified
And suddenly your segmentation logic starts drifting.
You’re still sending campaigns—but they’re no longer aligned with how that industry actually operates.
Compliance and Sensitivity Risks
Certain industries carry stricter communication expectations.
Not just in terms of regulations—but in how outreach is received.
Cheap providers don’t filter for:
Contact sensitivity
Role appropriateness
Communication boundaries
So your campaign might technically “deliver”…
but still land in the wrong context.
That’s where reply quality drops.
Not because your message is weak—but because it shouldn’t have been sent to that contact in the first place.
The Illusion of Coverage
Cheap datasets often feel comprehensive.
Thousands of contacts. Multiple companies. Broad coverage.
But coverage isn’t the same as accuracy.
When vertical-specific nuances are ignored, coverage becomes misleading:
You have contacts—but not the right ones
You have emails—but not the right roles
You have scale—but not alignment
This is why campaigns can look active…
yet produce weak or irrelevant replies.
Where It Starts to Show Up
You’ll usually notice it in subtle ways first:
Replies that say “not the right person”
Interest from roles that don’t match your ICP
Conversations that stall early
These aren’t random.
They’re signals that your data doesn’t match the vertical reality you’re targeting.
Teams working with reliable SaaS B2B lead datasets tend to avoid this because role mapping, company structure, and segmentation logic are aligned with how that industry actually functions—not just how it looks in a spreadsheet.
Why This Gets Misdiagnosed
Most teams don’t trace this back to the data.
They assume:
The message needs improvement
The offer isn’t strong enough
The timing is off
So they iterate on copy.
They tweak sequences.
They change subject lines.
But nothing really changes.
Because the issue wasn’t in the messaging layer.
It was already baked into the list.
What This Means
Vertical-specific risk isn’t obvious when you’re looking at rows and columns.
It only shows up when those rows interact with real people inside real industries.
That’s when assumptions break.
And once they do, every part of your outbound system starts compensating for something it can’t fix.
Clean data doesn’t just fill fields—it reflects how each industry actually operates.
When your dataset ignores those differences, your outreach doesn’t fail loudly—it just quietly misses the people who matter.
Related Post:
The AI Pipeline Behind Modern B2B Data Processing
Why LLM-Assisted Validation Requires Clean Metadata
The Vertical Variances That Predict ICP Fit Accuracy
How Industry Complexity Impacts Lead Quality Signals
Why Some Verticals Have Stronger Multi-Contact Data
The Channel-Specific Validation Gaps Most Teams Never Notice
How Contact Recency Impacts Phone Outreach More Than Email
Why LinkedIn Signals Reveal Intent Email Can’t Detect
The Geographic Accuracy Patterns Hidden in Lead Lists
How Cultural Factors Influence B2B Data Consistency
Why Contact Fields Behave Differently Across Regions
The Pricing Logic Behind High-Demand Industries
How Industry Growth Trends Impact Lead Cost
Why Validation Depth Changes Lead Prices by Industry
How Lead Recency Influences Inbox Placement More Than Subject Lines
The Recency-Driven Framework High-Performing Outbound Teams Use
Why Lead Lists Decay Faster in Certain Industries
Why Providers Overclaim Their Validation Accuracy
How Verification Depth Determines Your Cold Email Success
The Deliverability Risks Hidden in “Instant Validation” Tools
The Infrastructure Fragility Hidden in Cheap Lead Lists
How Data Drift Creates Bounce Surges Over Time
Why Even “Valid” Emails Can Bounce If Recency Is Off
Why Most Companies Discover Data Drift Only After It Hurts Revenue
The Structural Problems That Arise When Data Is Left Unmaintained
How Contact Aging Creates Metadata Conflicts in Your CRM
Why Missing Metadata Lowers the Accuracy of Your Filters
The Enrichment Framework Behind High-Performing Outbound
How Company Size Errors Create Misleading Pipelines
How Manual Review Prevents Domain Reputation Damage
The Validation Conflicts You Only Notice With Human Eyes
Why Automated Systems Misjudge Role-Based Emails
Why Sending to Spam Traps is Worse Than Hard Bounces
The Duplicate Clusters That Break Your Segmentation Flow
How Compromised Emails Drag Your Deliverability Down
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.