The Duplicate Clusters That Break Your Segmentation Flow
Duplicate clusters don’t just inflate your data — they distort segmentation logic. Learn how hidden duplication patterns break targeting, misroute campaigns, and quietly damage outbound performance.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
3/17/20263 min read
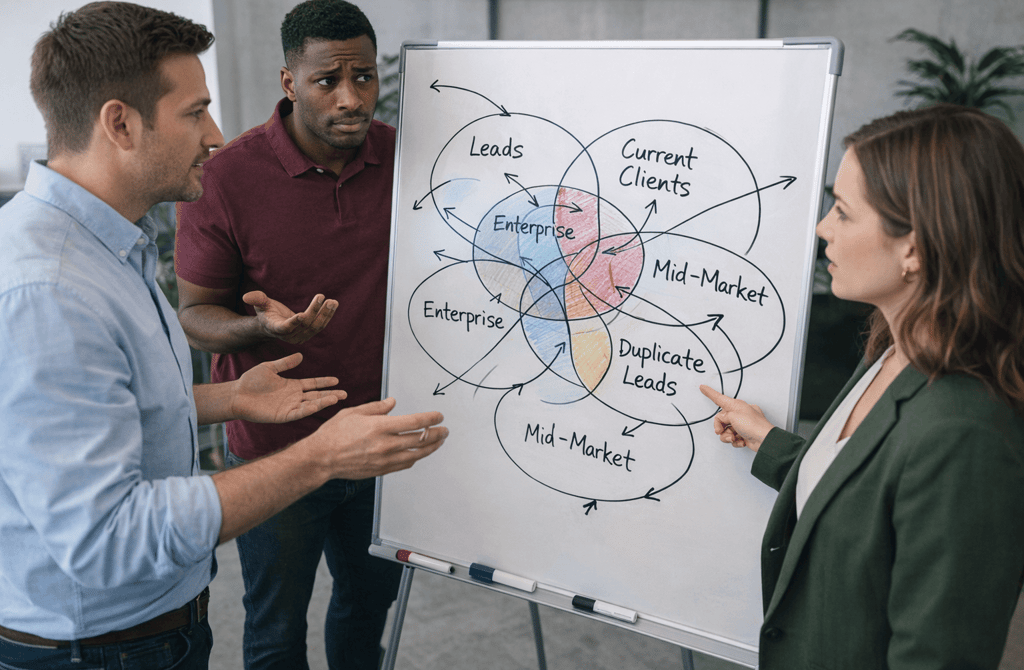
Segmentation doesn’t usually fail because of bad strategy.
It fails because the structure underneath it isn’t as clean as it looks.
You build segments. You define your ICP. You map out flows.
Everything feels aligned.
But once campaigns go live, something starts drifting.
Leads appear in the wrong sequences. Messaging overlaps. Performance becomes inconsistent across segments that should behave the same.
And it’s hard to pinpoint why.
The Problem Isn’t Just Duplicates — It’s Clusters
Most teams think of duplicates as isolated errors.
A repeated contact. A copied record. Something small.
But in practice, duplicates rarely exist alone.
They form clusters.
The same company appears multiple times under slightly different names. The same contact exists with different titles. The same account gets pulled into multiple segments because of minor data variations.
Individually, each entry looks valid.
Collectively, they break the logic of your segmentation.
How Clusters Distort Segmentation Logic
Segmentation relies on clean boundaries.
When those boundaries blur, systems stop behaving predictably.
A single account might end up in:
Multiple campaign sequences at once
Different messaging angles that conflict with each other
Separate reporting buckets that inflate performance
Now your segmentation isn’t organizing your outreach.
It’s duplicating it.
And because everything still “runs,” the issue stays hidden.
When the System Starts Working Against You
This is where things get expensive.
Instead of clean targeting, you get:
Overlapping outreach that confuses prospects
Misleading insights from segmented performance reports
You might think one segment is outperforming another.
But in reality, you’re just hitting the same accounts more than once from different angles.
That’s not segmentation.
That’s noise disguised as structure.
Why This Doesn’t Show Up Immediately
Duplicate clusters don’t break your system overnight.
They create subtle inconsistencies.
A campaign underperforms, but not enough to panic.
A segment behaves differently, but not enough to investigate.
So you adjust messaging. You tweak flows. You experiment with timing.
But none of those fixes address the root issue.
Because the problem isn’t how you’re reaching people.
It’s how your system defines who they are.
The Role of Data Consistency
Segmentation only works when each account has a single, consistent identity.
Once that breaks, everything downstream starts drifting.
Teams working with structured manufacturing company lead data often avoid this issue because consistent firmographic standardization reduces how often the same company is split into multiple records.
It’s not about having more data.
It’s about having data that behaves consistently inside a system.
What This Means for Your Outbound
If segmentation is supposed to create clarity, duplicate clusters do the opposite.
They multiply paths, blur ownership, and distort feedback.
And the more you scale outbound, the more those distortions compound.
So before refining messaging or adding new segments, it’s worth asking:
Are your segments actually clean?
Or are they quietly overlapping in ways your system isn’t built to handle?
What This Means
Segmentation only works when the structure behind it holds.
Once duplicate clusters start forming, your system doesn’t break — it drifts.
And that drift is harder to detect than failure.
Clean segmentation depends on consistent data boundaries that don’t overlap.
Duplicate-heavy data turns targeting into repetition, not precision.
Related Post:
The AI Pipeline Behind Modern B2B Data Processing
Why LLM-Assisted Validation Requires Clean Metadata
The Vertical Variances That Predict ICP Fit Accuracy
How Industry Complexity Impacts Lead Quality Signals
Why Some Verticals Have Stronger Multi-Contact Data
The Channel-Specific Validation Gaps Most Teams Never Notice
How Contact Recency Impacts Phone Outreach More Than Email
Why LinkedIn Signals Reveal Intent Email Can’t Detect
The Geographic Accuracy Patterns Hidden in Lead Lists
How Cultural Factors Influence B2B Data Consistency
Why Contact Fields Behave Differently Across Regions
The Pricing Logic Behind High-Demand Industries
How Industry Growth Trends Impact Lead Cost
Why Validation Depth Changes Lead Prices by Industry
How Lead Recency Influences Inbox Placement More Than Subject Lines
The Recency-Driven Framework High-Performing Outbound Teams Use
Why Lead Lists Decay Faster in Certain Industries
Why Providers Overclaim Their Validation Accuracy
How Verification Depth Determines Your Cold Email Success
The Deliverability Risks Hidden in “Instant Validation” Tools
The Infrastructure Fragility Hidden in Cheap Lead Lists
How Data Drift Creates Bounce Surges Over Time
Why Even “Valid” Emails Can Bounce If Recency Is Off
Why Most Companies Discover Data Drift Only After It Hurts Revenue
The Structural Problems That Arise When Data Is Left Unmaintained
How Contact Aging Creates Metadata Conflicts in Your CRM
Why Missing Metadata Lowers the Accuracy of Your Filters
The Enrichment Framework Behind High-Performing Outbound
How Company Size Errors Create Misleading Pipelines
How Manual Review Prevents Domain Reputation Damage
The Validation Conflicts You Only Notice With Human Eyes
Why Automated Systems Misjudge Role-Based Emails
Why Sending to Spam Traps is Worse Than Hard Bounces
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.