The Hidden Biases AI Introduces When Data Is Weak
When input data is weak, AI systems amplify bias instead of accuracy. Here’s how poor data quality distorts AI-driven lead decisions.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
1/24/20263 min read
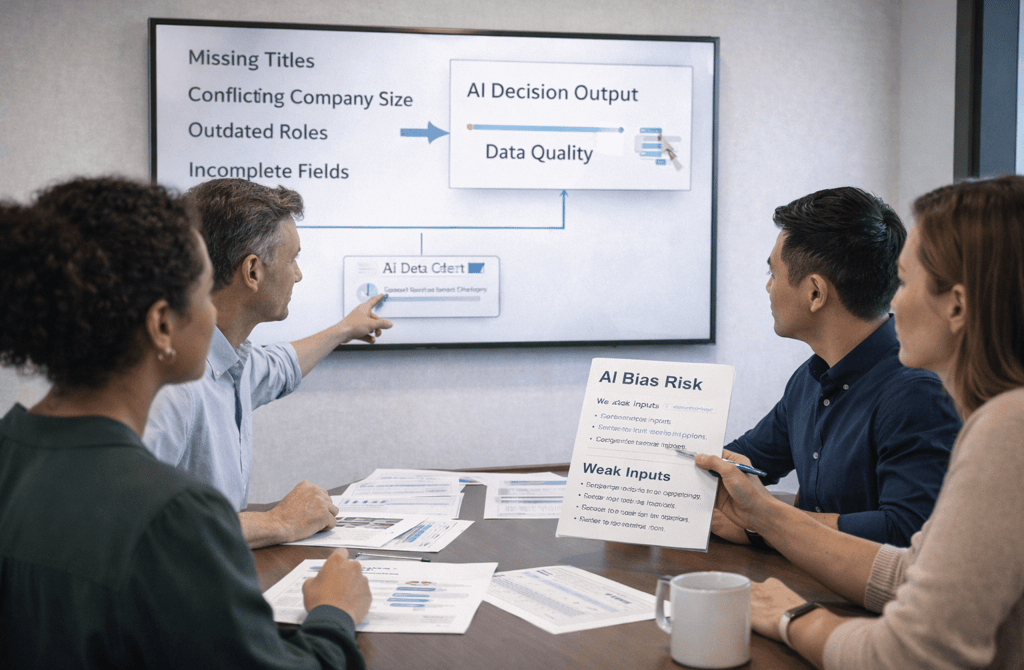
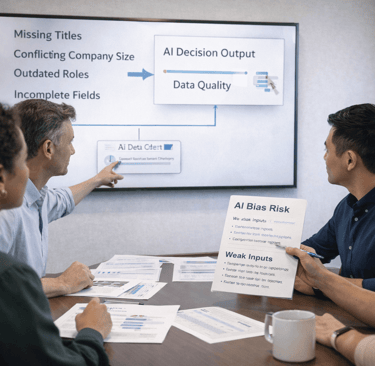
Bias doesn’t usually enter AI systems through intent.
It enters through absence.
Missing fields, partial records, outdated attributes — these gaps force AI systems to infer. And inference, by definition, is where bias forms. Not because the model is careless, but because it has to choose something when the signal isn’t there.
In outbound data, that choice has consequences.
Why weak data doesn’t stay neutral inside AI systems
AI models don’t treat missing information as empty space.
They treat it as a problem to solve.
When data is weak, AI compensates by leaning on:
historical averages
dominant patterns in the training set
assumptions that worked “often enough” before
This creates bias not toward truth, but toward what is most statistically common, even when it’s wrong for the current record.
That’s not a bug. It’s how probabilistic systems behave under uncertainty.
The quiet way bias compounds in lead decisions
Bias rarely shows up as obvious errors.
It shows up as consistent misjudgment.
Examples:
senior titles over-weighted because they appear more often in past wins
certain industries flagged as higher quality because of historical response density
company size assumptions filling gaps when revenue data is missing
Individually, these seem reasonable. At scale, they skew entire segments.
The danger isn’t one bad lead — it’s systematic preference created by incomplete inputs.
Why AI bias is often invisible to teams
Here’s the uncomfortable part: biased AI decisions often look cleaner than reality.
They’re:
internally consistent
confidently scored
easy to operationalize
Because the model resolves uncertainty instead of exposing it, teams rarely see what was assumed versus what was known.
Manual review catches obvious mistakes.
It doesn’t catch silent substitution.
Weak data pushes AI toward false certainty
When inputs are strong, AI can compare, cross-check, and balance signals.
When inputs are weak, AI does the opposite:
it narrows variance
it reduces ambiguity
it commits earlier
This creates false confidence — records that look well-scored but are actually built on thin foundations.
The model isn’t biased because it’s aggressive.
It’s biased because it’s forced to decide without enough context.
Where this shows up in outbound performance
These biases don’t announce themselves as “AI problems.”
They surface as:
roles that never reply despite “high confidence”
industries that look viable on paper but stall in practice
Teams respond by adjusting copy, cadence, or volume — while the bias remains untouched.
The system keeps reinforcing its own assumptions because outcomes never correct the input gap.
Why better models don’t fix weak data bias
More advanced models don’t remove this problem.
They often amplify it.
Smarter models infer faster, generalize more confidently, and extrapolate further. Without strong data boundaries, they become better at being wrong in consistent ways.
Bias is not solved by intelligence.
It’s solved by constraint.
The role of human judgment in bias control
Humans are not better at scale.
They are better at noticing absence.
A reviewer can say:
“We actually don’t know this”
“This assumption feels forced”
“This pattern doesn’t apply here”
AI-assisted systems work best when they:
surface uncertainty instead of hiding it
flag weak-input decisions
preserve ambiguity where confidence would be misleading
Bias control isn’t about removing AI.
It’s about preventing AI from filling gaps silently.
What this means operationally
Weak data doesn’t just reduce accuracy.
It reshapes decision logic.
When AI is forced to guess, it builds preferences.
When preferences go unchallenged, they become structural.
Clean data doesn’t eliminate bias — but it limits where bias can form.
And systems that expose uncertainty make better decisions than systems that resolve it too early.
Related Post:
The Chain Reactions Triggered by Weak Data Inputs
How One Bad Field Corrupts an Entire Outbound System
Why Data Dependencies Matter More Than Individual Signals
The Upstream Errors That Create Downstream Pipeline Damage
Why Some Industries Naturally Produce Higher Bounce Rates
The Vertical Patterns Behind High-Bounce Lead Lists
How Industry Type Predicts Email Bounce Probability
Why Low-Bounce Verticals Offer More Stable Outreach
The Structural Reasons Certain Verticals Bounce More
Why Outbound Behavior Differs Wildly Across Verticals
The Industry-Level Reply Patterns Most Teams Miss
How Vertical Dynamics Shape Cold Email Engagement
Why Some Industries Respond Faster Than Others
The Vertical Factors Behind High-Intent Replies
Why Some Industries Experience Lightning-Fast Data Decay
The Vertical Decay Speed Patterns Most Teams Never Measure
How Industry Turnover Dictates Data Decay Velocity
Why High-Pace Markets Produce Faster-Expiring Lead Data
The Decay-Speed Differences Between Tech and Traditional Verticals
The AI Signal Patterns That Predict Lead Reliability
How Machine Learning Improves Multi-Field Enrichment
Why AI-Assisted Verification Outperforms Manual Checks Alone
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.