How Machine Learning Improves Multi-Field Enrichment
Machine learning improves B2B enrichment by resolving conflicts across titles, company data, and signals—without relying on single-field guesses.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
1/24/20263 min read
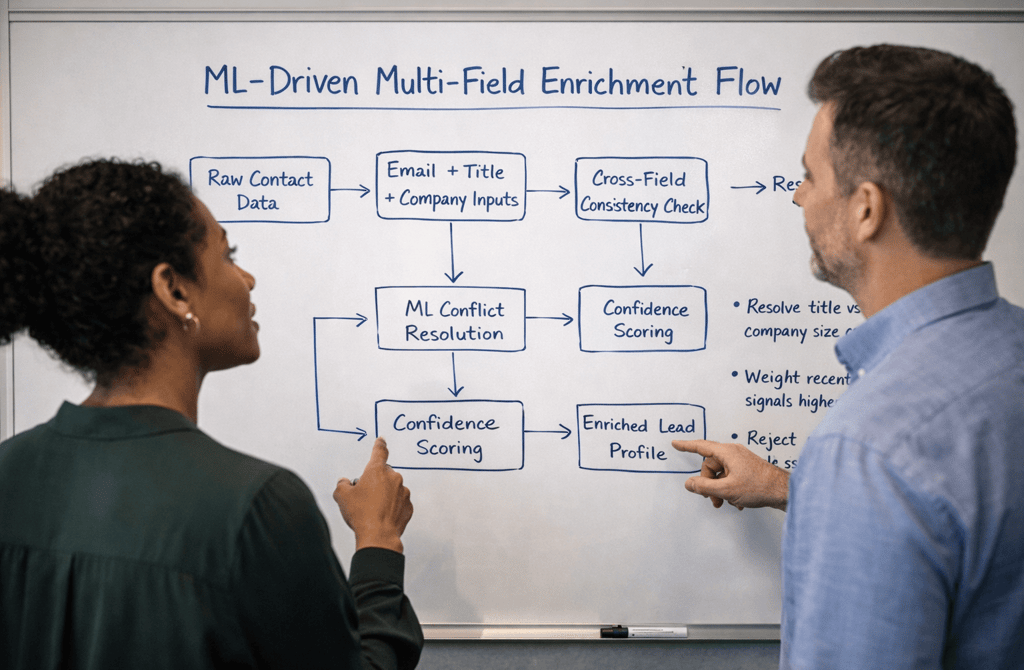
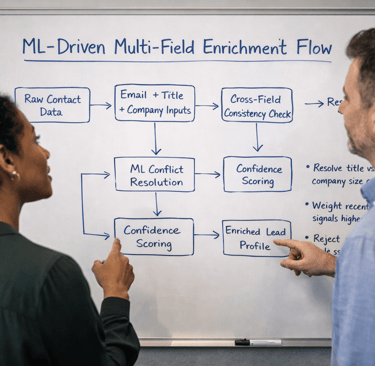
Most enrichment problems don’t come from missing data.
They come from data that disagrees with itself.
An email looks valid, a title looks senior, the company size looks small — and suddenly the record makes no sense as a whole. Human reviewers spot this instinctively. Traditional enrichment tools don’t.
This is where machine learning changes the game.
Why Single-Field Enrichment Breaks at Scale
Classic enrichment systems treat fields independently:
find an email
attach a title
attach a company record
Each field may be “correct” on its own, but correctness in isolation doesn’t equal accuracy in combination.
The result:
senior titles attached to tiny firms
mismatched departments
inflated ICP confidence
The problem isn’t missing data — it’s unresolved conflict.
Multi-Field Enrichment Is a Reconciliation Problem
True enrichment is not about filling blanks.
It’s about deciding which version of reality wins when fields collide.
Machine learning reframes enrichment as:
pattern reconciliation
probability balancing
confidence weighting
Instead of asking “Is this field valid?”, ML asks:
“Does this field make sense relative to the others?”
How Machine Learning Resolves Field Conflicts
1. Contextual Field Weighting
Not all fields deserve equal trust.
Machine learning learns when to:
trust recent signals more than historical ones
downweight fields that frequently drift
This weighting changes dynamically based on industry, role type, and company stage.
2. Cross-Field Consistency Checks
ML models evaluate relationships, not just values.
They test questions like:
Does this title normally exist at companies of this size?
Do similar companies use this role naming pattern?
Does this department align with known buying structures?
When inconsistencies appear, enrichment confidence drops — even if no single field is technically wrong.
3. Learning From Resolution Outcomes
Every resolved conflict feeds the system.
Machine learning tracks:
which resolutions led to replies
which produced bounces or silence
which created downstream pipeline issues
Over time, enrichment decisions improve because the model learns which combinations actually work in outbound environments.
4. Rejecting “Looks Right” Data
One of the biggest upgrades ML brings is restraint.
Instead of force-filling every record, ML systems:
withhold enrichment when confidence is low
flag records instead of guessing
preserve uncertainty rather than masking it
This prevents false precision — a major cause of outbound failure.
Why This Matters for Outbound Performance
Multi-field enrichment affects more than targeting.
It shapes:
personalization relevance
deliverability signals
reply consistency
When fields align, outreach feels smoother.
When they don’t, teams overcorrect copy, cadence, or volume — without realizing the data itself is unstable.
Machine Learning vs Rule-Based Enrichment
Rules are static.
Markets aren’t.
Rule-based systems struggle with:
new role titles
shifting org structures
industry-specific naming drift
Machine learning adapts by observing how data behaves over time, not how it was defined once.
That adaptability is what makes enrichment durable.
What This Means in Practice
High-quality enrichment isn’t louder or more detailed.
It’s coherent.
Machine learning improves enrichment by ensuring that:
fields support each other
confidence reflects reality
records behave predictably once used
The goal isn’t more data.
It’s fewer contradictions.
Bottom Line
Machine learning doesn’t make enrichment smarter by adding fields.
It makes it smarter by resolving disagreement between them.
When enrichment focuses on coherence instead of completion, outbound systems stop compensating for data problems — and start operating on information they can trust.
Reliable outreach doesn’t start with more inputs.
It starts with data that makes sense as a whole.
Related Post:
The Chain Reactions Triggered by Weak Data Inputs
How One Bad Field Corrupts an Entire Outbound System
Why Data Dependencies Matter More Than Individual Signals
The Upstream Errors That Create Downstream Pipeline Damage
Why Some Industries Naturally Produce Higher Bounce Rates
The Vertical Patterns Behind High-Bounce Lead Lists
How Industry Type Predicts Email Bounce Probability
Why Low-Bounce Verticals Offer More Stable Outreach
The Structural Reasons Certain Verticals Bounce More
Why Outbound Behavior Differs Wildly Across Verticals
The Industry-Level Reply Patterns Most Teams Miss
How Vertical Dynamics Shape Cold Email Engagement
Why Some Industries Respond Faster Than Others
The Vertical Factors Behind High-Intent Replies
Why Some Industries Experience Lightning-Fast Data Decay
The Vertical Decay Speed Patterns Most Teams Never Measure
How Industry Turnover Dictates Data Decay Velocity
Why High-Pace Markets Produce Faster-Expiring Lead Data
The Decay-Speed Differences Between Tech and Traditional Verticals
The AI Signal Patterns That Predict Lead Reliability
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.