The Hidden Errors Found in Multi-Site Organizations
Multi-site organizations often carry hidden data errors that quietly distort targeting, segmentation, and outreach accuracy. Learn how these inconsistencies form, where they appear, and how they impact outbound performance.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
3/19/20264 min read
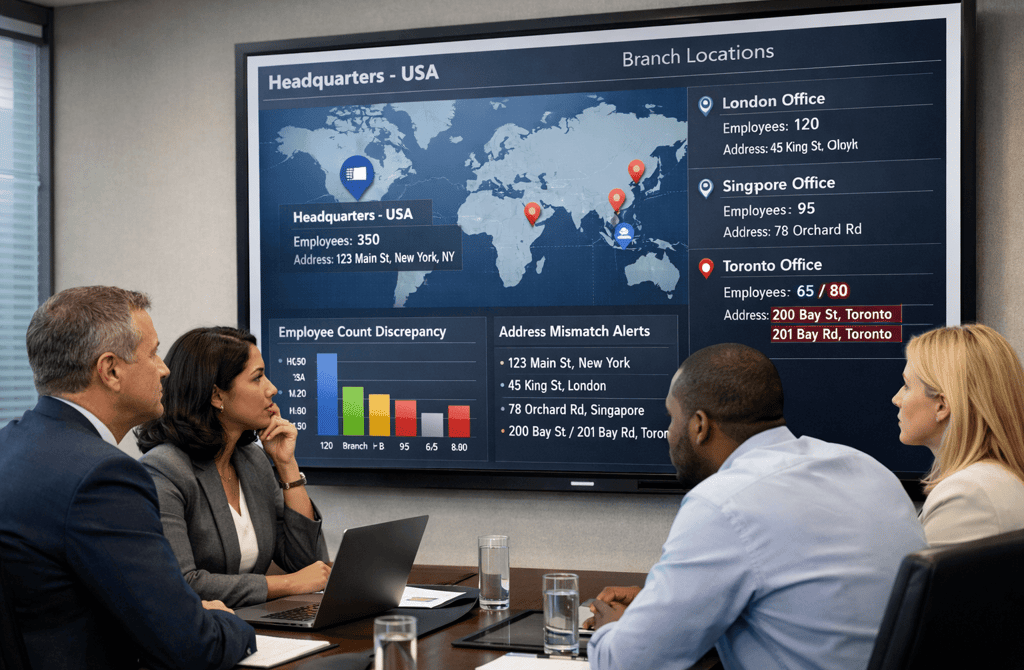

At first glance, multi-site organizations look like a scaling advantage.
More locations. More coverage. More reach.
But underneath that structure, something subtle starts to break.
Not loudly. Not immediately.
Quietly.
Because the moment a company operates across multiple sites, data stops behaving like a single system—and starts behaving like fragments pretending to be one.
The Illusion of a Single Company Record
Most outbound systems assume one company equals one truth.
One employee count. One headquarters. One set of decision-makers.
That assumption works—until it doesn’t.
Multi-site organizations introduce multiple versions of the same company, each shaped by location-specific updates. A branch updates its headcount. Another location changes its leadership. A regional office uses a different naming format.
None of these changes are wrong.
But they’re not aligned either.
And that’s where the illusion begins.
Because what looks like one clean company record is actually a collection of slightly conflicting truths stitched together.
Where the Errors Actually Form
These errors don’t come from bad data providers.
They come from structural drift.
Each location feeds information into systems at different times, from different sources, under different standards. Over time, this creates:
Variations in employee counts across records
Multiple headquarters labels depending on data source
Different contact roles tied to different locations
Inconsistent company naming formats
Individually, these seem minor.
But collectively, they create a versioning problem.
You’re not targeting a company anymore.
You’re targeting whichever version of that company your system happens to surface.
Why This Breaks Outbound Without You Noticing
The problem isn’t that the data is wrong.
The problem is that it’s inconsistently right.
And outbound systems aren’t built to handle that nuance.
So what happens?
A campaign pulls a contact tied to a regional office, but the messaging assumes a global role. Another sequence targets a company size that reflects a single branch, not the entire organization. Segmentation logic groups companies incorrectly because location-level data overrides company-level signals.
Nothing crashes.
Nothing alerts you.
But performance starts to feel off.
Reply quality drops. Conversions stall. Messaging feels “close, but not quite there.”
And it’s hard to diagnose—because every individual data point looks valid on its own.
The Compounding Effect Inside Your CRM
Once these inconsistencies enter your CRM, they don’t stay isolated.
They multiply.
Duplicate company profiles emerge, each tied to different locations. Contacts get assigned to the wrong entity. Revenue attribution becomes fragmented because deals are linked to inconsistent records.
Over time, your system starts telling conflicting stories:
One report shows growth
Another shows stagnation
A third shows inflated pipeline
All based on the same organization.
This isn’t a visibility problem.
It’s a structural integrity problem.
Why Fixing It Isn’t Just “Cleaning Data”
Most teams respond by trying to clean or deduplicate.
But that approach treats the symptom, not the system.
Because the issue isn’t duplication alone.
It’s the lack of hierarchy between global and location-level data.
Without clear relationships between headquarters and branches, your system keeps flattening everything into one layer—where conflicts are inevitable.
Fixing this requires something different:
Not just cleaner records.
But context-aware structure.
What This Means for Targeting and Segmentation
Multi-site organizations require a different lens.
You’re not just targeting companies.
You’re targeting organizational layers.
That means understanding:
Which contacts operate at global vs local levels
Which data points reflect the entire organization vs a single site
Which signals should override others when conflicts appear
This is why teams working with structured construction industry lead data tend to avoid these breakdowns—because structured datasets enforce consistency between company-level and location-level attributes, preventing overlap before it starts.
Without that structure, segmentation becomes guesswork.
And guesswork doesn’t scale.
The Real Takeaway
Multi-site organizations don’t break your outbound overnight.
They slowly distort it.
What looks like minor inconsistencies at the record level becomes major misalignment at the campaign level. And because each piece of data is technically “correct,” the system never flags the issue.
You just feel it in performance.
And by the time it’s obvious, it’s already baked into your pipeline.
When company data fragments across locations, targeting loses its foundation and messaging starts drifting without direction.
When organizational structure isn’t reflected in your data, outbound stops aligning with reality—even if every record looks accurate.
Related Post:
The Channel-Specific Validation Gaps Most Teams Never Notice
How Contact Recency Impacts Phone Outreach More Than Email
Why LinkedIn Signals Reveal Intent Email Can’t Detect
The Geographic Accuracy Patterns Hidden in Lead Lists
How Cultural Factors Influence B2B Data Consistency
Why Contact Fields Behave Differently Across Regions
The Pricing Logic Behind High-Demand Industries
How Industry Growth Trends Impact Lead Cost
Why Validation Depth Changes Lead Prices by Industry
How Lead Recency Influences Inbox Placement More Than Subject Lines
The Recency-Driven Framework High-Performing Outbound Teams Use
Why Lead Lists Decay Faster in Certain Industries
Why Providers Overclaim Their Validation Accuracy
How Verification Depth Determines Your Cold Email Success
The Deliverability Risks Hidden in “Instant Validation” Tools
The Infrastructure Fragility Hidden in Cheap Lead Lists
How Data Drift Creates Bounce Surges Over Time
Why Even “Valid” Emails Can Bounce If Recency Is Off
Why Most Companies Discover Data Drift Only After It Hurts Revenue
The Structural Problems That Arise When Data Is Left Unmaintained
How Contact Aging Creates Metadata Conflicts in Your CRM
Why Missing Metadata Lowers the Accuracy of Your Filters
The Enrichment Framework Behind High-Performing Outbound
How Company Size Errors Create Misleading Pipelines
How Manual Review Prevents Domain Reputation Damage
The Validation Conflicts You Only Notice With Human Eyes
Why Automated Systems Misjudge Role-Based Emails
Why Sending to Spam Traps is Worse Than Hard Bounces
The Duplicate Clusters That Break Your Segmentation Flow
How Compromised Emails Drag Your Deliverability Down
The Vertical-Specific Risks Cheap Providers Ignore
How Industry Growth Rates Alter Lead Accuracy
Why Some Industries Generate More Role-Based Emails
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.