How Bad Data Corrupts Lead Prioritization Models
Bad data doesn’t just lower lead quality — it actively corrupts prioritization models. Learn how inaccurate inputs skew scores, rankings, and pipeline decisions.
INDUSTRY INSIGHTSLEAD QUALITY & DATA ACCURACYOUTBOUND STRATEGYB2B DATA STRATEGY
CapLeads Team
1/11/20263 min read
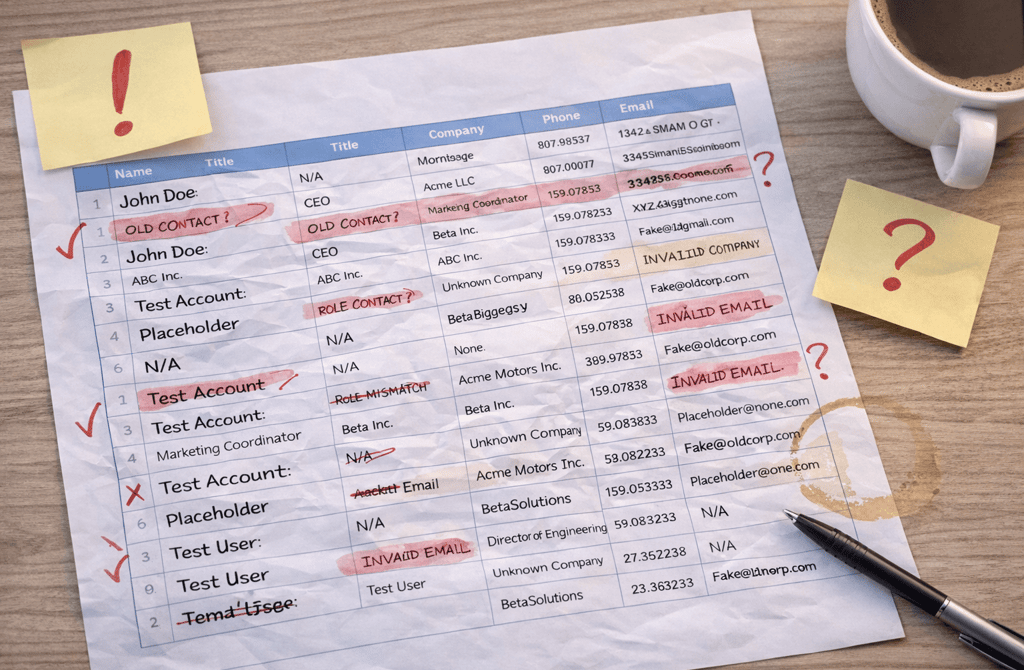
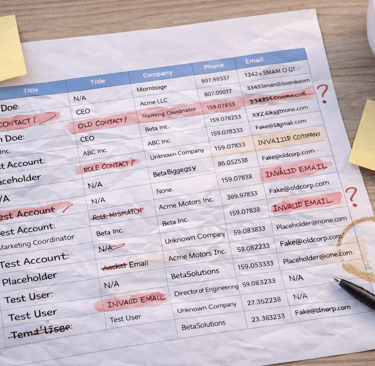
Lead prioritization models are designed to answer one question: who should we focus on next? When they work, SDRs move faster, pipelines advance more smoothly, and effort is spent where it actually matters.
When they don’t, teams assume the model needs tuning.
In reality, most prioritization models aren’t failing because of poor logic. They’re being quietly corrupted by bad data long before any scoring rules are applied.
This corruption doesn’t show up as an obvious error. It shows up as distorted rankings, misplaced urgency, and a pipeline that looks busy but doesn’t progress.
Prioritization models don’t “understand” bad data — they normalize it
A prioritization model doesn’t question inputs. It assumes they’re usable.
If a job title is wrong, the model still assigns weight.
If company size is inflated, it still boosts priority.
If records are duplicated, it still stacks signals.
Bad data doesn’t break the system outright. It reshapes it.
Over time, the model begins to treat incorrect patterns as normal behavior. That’s when prioritization stops reflecting reality and starts reinforcing noise.
Ranking distortion is the most dangerous failure mode
The most damaging effect of bad data isn’t low scores — it’s wrong order.
Leads that should be mid-priority float to the top.
Leads that should be excluded remain ranked as “worth a try.”
High-fit accounts get buried under inflated but low-quality records.
Because the model still produces a ranked list, teams trust it. SDRs follow it. Managers report on it. But the order itself is compromised.
This is why teams often feel like they’re “working hard but going nowhere.” The effort is real. The prioritization isn’t.
Duplicate and inconsistent records amplify false urgency
Bad data rarely comes clean. It clusters.
The same account appears multiple times with slight variations.
The same contact exists under different titles.
Engagement signals get split or duplicated.
Prioritization models interpret this as momentum. Multiple records with partial engagement look like strong interest when combined, even though they represent fragmented or outdated data.
This creates false urgency — leads that appear active but don’t convert when contacted.
Missing fields silently flatten priority differences
Prioritization depends on contrast. The model needs enough signal variance to separate “must-contact” from “maybe later.”
When key fields are missing or inconsistently filled:
Seniority differences blur
Industry relevance weakens
Company size tiers collapse
The model compensates by leaning harder on whatever data is present, often low-quality engagement signals. This flattens the list, making everything look equally important — or equally mediocre.
At that point, prioritization becomes subjective again, defeating the purpose of the model entirely.
Bad data trains teams to ignore the model
There’s a downstream human cost to corrupted prioritization.
SDRs notice when top-ranked leads don’t reply.
Managers notice when “high priority” accounts stall.
Founders notice when pipeline forecasts miss repeatedly.
Eventually, people stop trusting the model. They cherry-pick. They override scores. They revert to gut instinct.
This isn’t because prioritization models don’t work. It’s because bad data erodes confidence faster than any technical flaw.
Why fixing logic before fixing data makes things worse
When prioritization feels off, teams often respond by:
Adding more scoring rules
Adjusting weights
Introducing new intent signals
But layering logic on top of corrupted inputs doesn’t improve accuracy — it compounds distortion.
More rules mean more places for bad data to influence outcomes. The model becomes more complex but less reliable, and diagnosing issues becomes nearly impossible.
Clean inputs simplify prioritization. Dirty inputs demand endless tuning.
What healthy prioritization actually looks like
When data quality is high, prioritization models behave differently:
Rankings stay stable over time
Top leads convert at a higher rate
Lower-priority leads clearly belong there
Overrides become rare, not routine
Most importantly, pipeline movement aligns with priority. The list doesn’t just look good — it predicts progress.
That’s the signal that the model isn’t being corrupted upstream.
Final thought
Lead prioritization models don’t fail loudly when data is bad. They fail quietly, by ranking the wrong leads with confidence.
When inputs are accurate, current, and consistent, prioritization becomes a reliable guide for action.
When data quality slips, even the best models turn pipeline decisions into educated guesses instead of dependable signals.
Related Post:
Why Intent Signals Predict Replies Better Than Copy
The Behavioral Clues That Reveal High-Intent Prospects
How Hidden Intent Patterns Shape Cold Email Outcomes
Why High-Intent Leads Respond Faster and More Consistently
The Intent Signals Most Outbound Teams Never Track
Why Reply Rates Depend More on Data Than Messaging
The Hidden Predictors of High Reply Probability
How Lead Quality Shapes Your Reply Rate Curve
Why Clean Lists Produce More Consistent Replies
The Timing Factors That Influence Reply Behavior
Why Data Problems Create Invisible Pipeline Leaks
The Silent Funnel Drop-Offs Caused by Weak Lead Quality
How Bad Data Corrupts Every Stage of Your Pipeline
Why Pipeline Inflation Happens With Outdated Leads
The Hidden Pipeline Leaks Most Founders Never Detect
Why CRM Cleanliness Determines Whether Outbound Scales
The Hidden CRM Errors That Break Your Entire Funnel
How Dirty CRM Records Create Pipeline Confusion
Why CRM Drift Happens Faster Than Teams Expect
The CRM Hygiene Rules That Protect Your Outbound System
Why Lead Scoring Fails Without Clean Data
The Scoring Indicators That Predict Real Pipeline Movement
Connect
Get verified leads that drive real results for your business today.
www.capleads.org
© 2025. All rights reserved.
Serving clients worldwide.
CapLeads provides verified B2B datasets with accurate contacts and direct phone numbers. Our data helps startups and sales teams reach C-level executives in FinTech, SaaS, Consulting, and other industries.